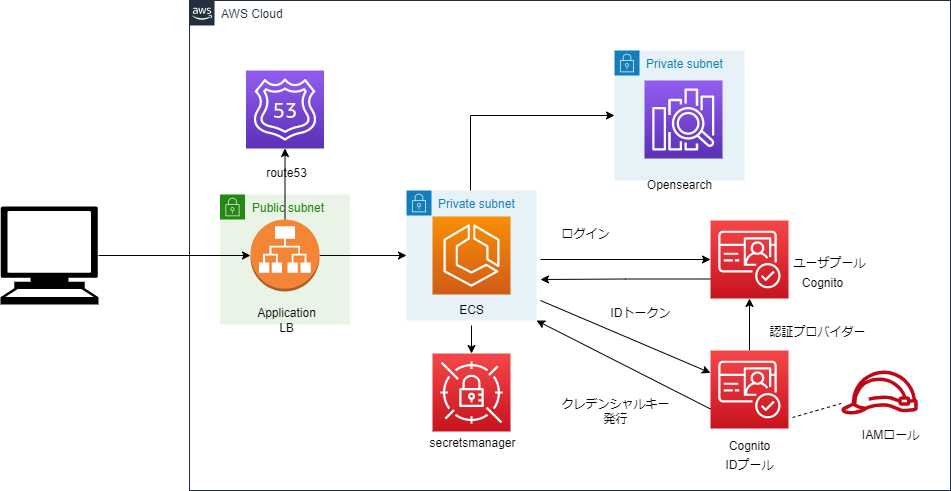
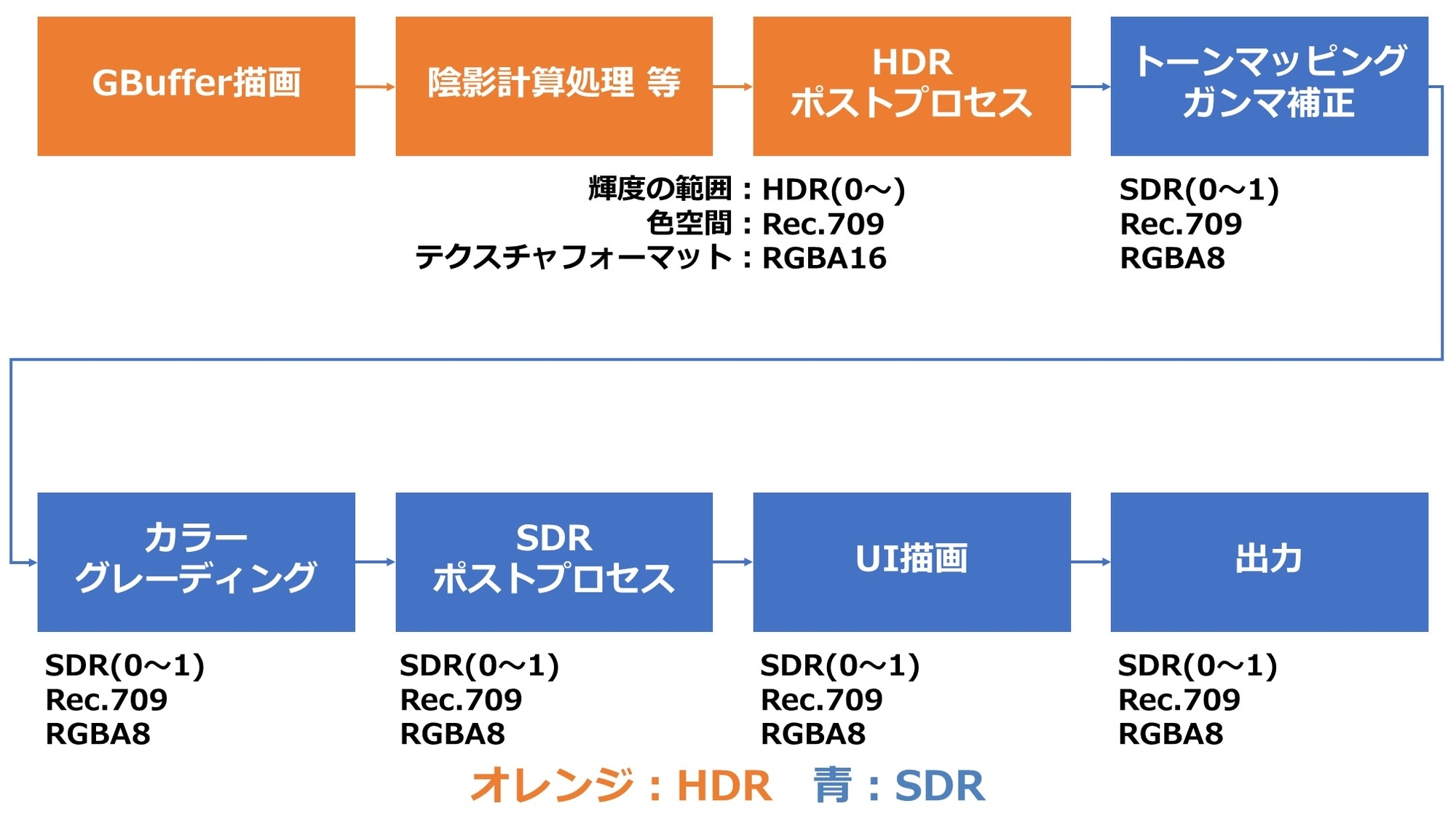
1.はじめに
株式会社セガ 第3事業部 第3オンライン研究開発プログラム1部の釘田と申します。
連日の寒さも徐々に明け、春の訪れを感じる頃合いです。
今年の冬は何度か弊社オフィスのある大崎でも雪が降りました。

私はこれまで雪のあまり降らない地域で過ごしてきたこともあり、
雪が積もるとつい童心に帰り、雪の上を歩きたくなります。
この雪の上で跡が付く様子ですが、ゲームではどのように表現されているでしょうか?
今回の記事では『ファンタシースターオンライン2 ニュージェネシス』における
雪原の跡付け表現について紹介したいと思います。
2.目次
3.前置き
記事内の画像は開発時のゲーム画面となります。
実際にリリースされているゲーム画面とは異なる場合もありますので、あらかじめご了承ください。
また、以降『ファンタシースターオンライン2ニュージェネシス』のことを『NGS』と表記します。
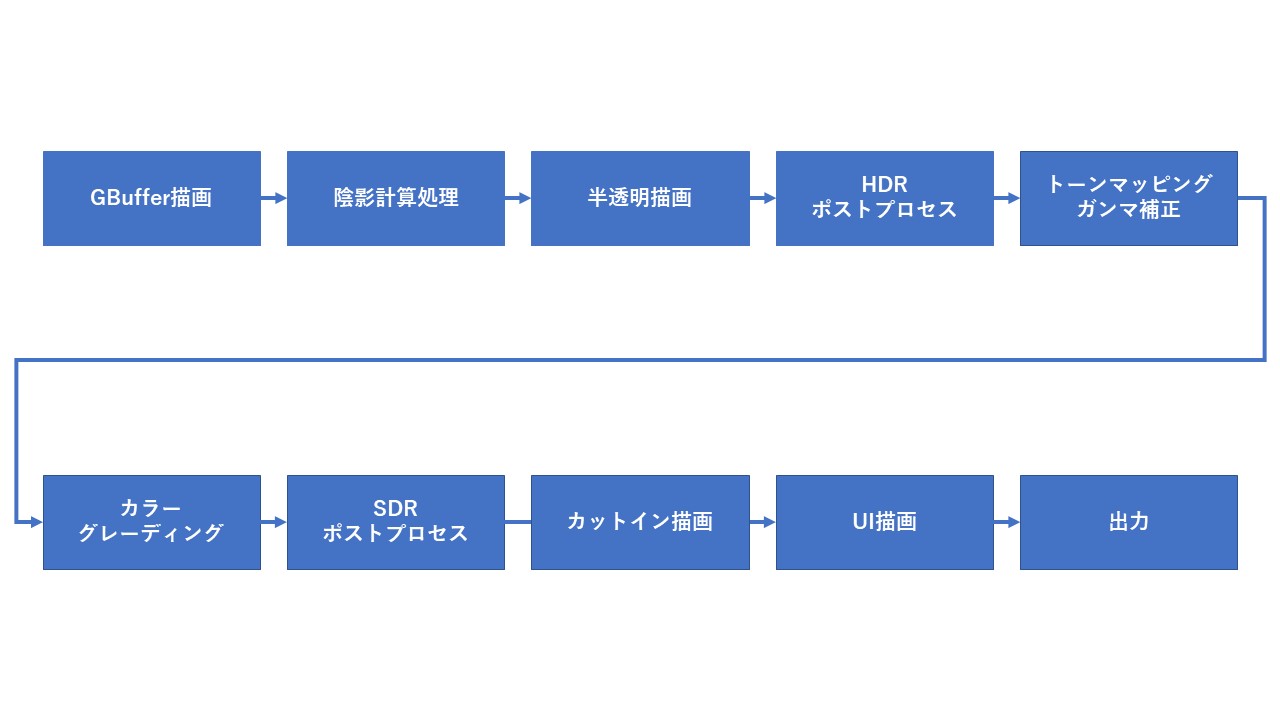
4.フィールドでの雪原の跡付け表現
まず、『NGS』における雪と氷のフィールドである「クヴァリス」での雪原の跡付け表現について説明します。
「クヴァリス」では一部の雪原において、キャラクターが歩いた場所に足跡が残ります。

4.1.キャラクターの足跡表現
足跡を雪原に残すにはどうすればいいでしょうか?
まずは実際に現実世界で雪がどのようにしてへこむかについて考えてみましょう。
冒頭の写真のような雪が積もった道を思い浮かべてみてください。
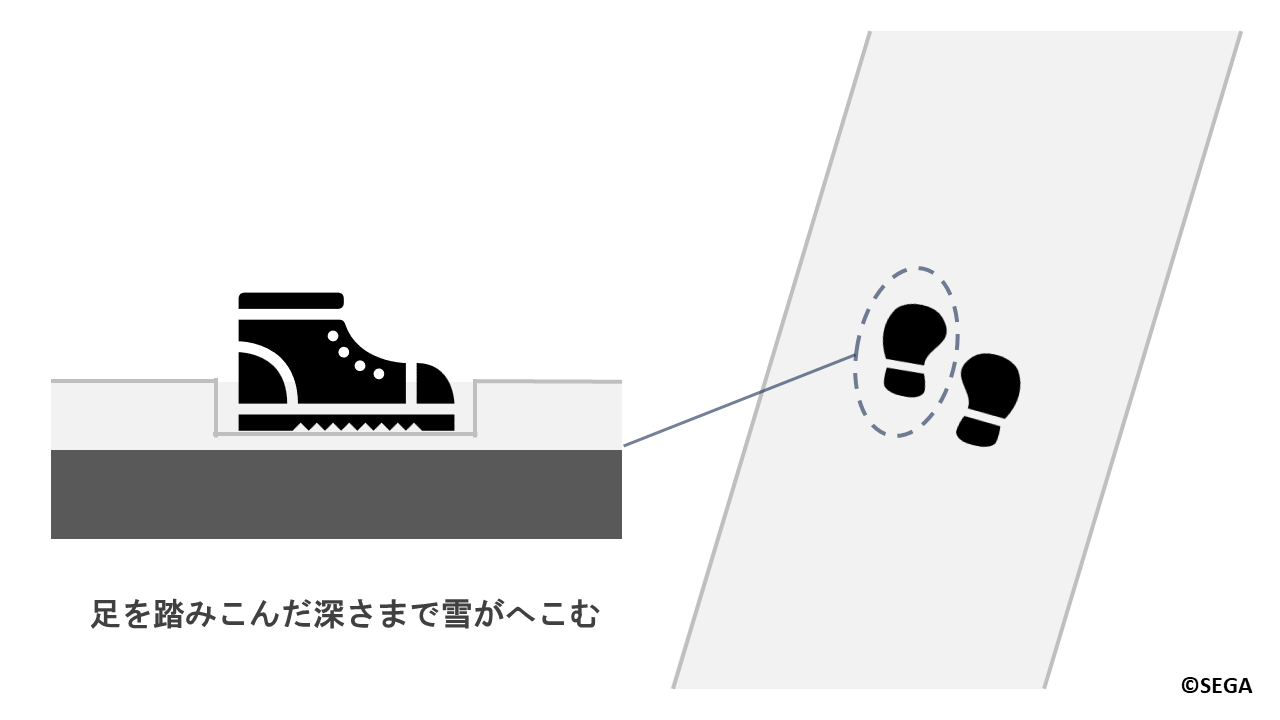
雪は柔らかいため、足を踏み入れると雪が積もっていた高さから踏み込んだ深さまでへこみ、足跡として残ります。
『NGS』では、地面の高さを雪の厚みの分だけ上昇させ、キャラクターが歩いた場所をへこませています。
これは以下のような処理で実現できそうです。
- 地形とキャラクターに対する深度撮影
- 軌跡テクスチャの作成
- 雪面の変形
それでは実際の処理について見ていきましょう。
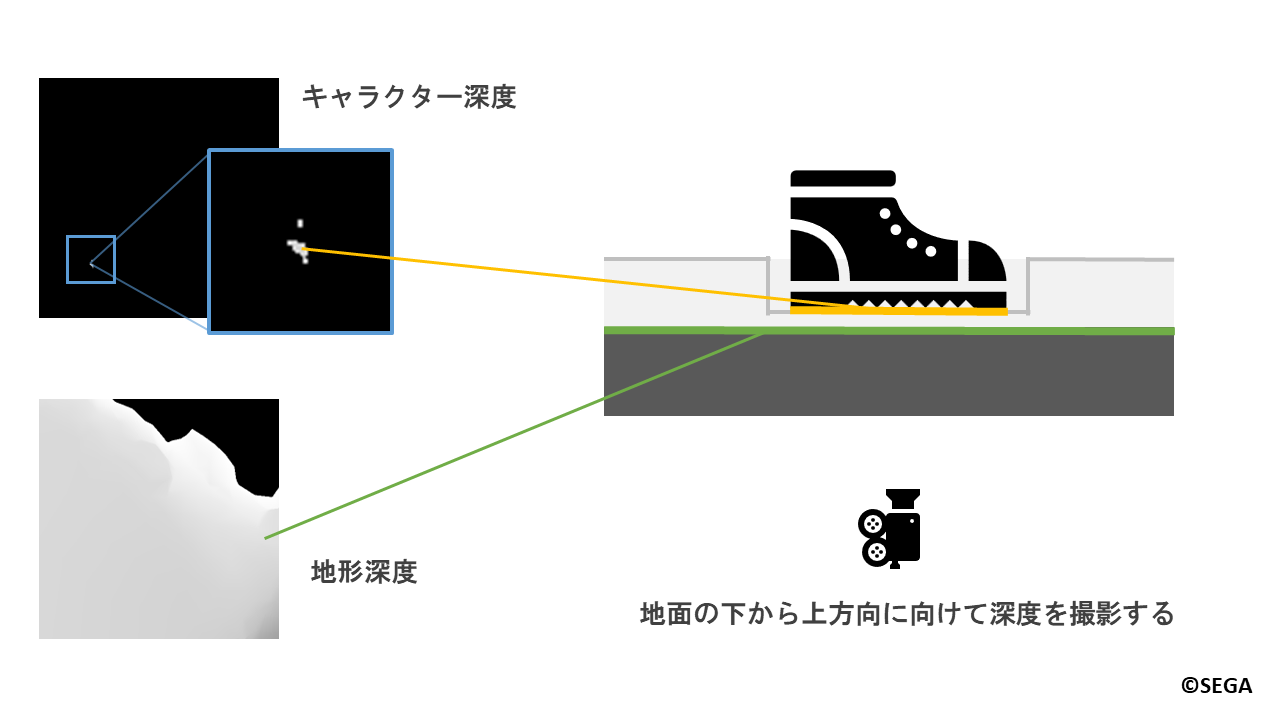
4.1.1.地形とキャラクターに対する深度撮影
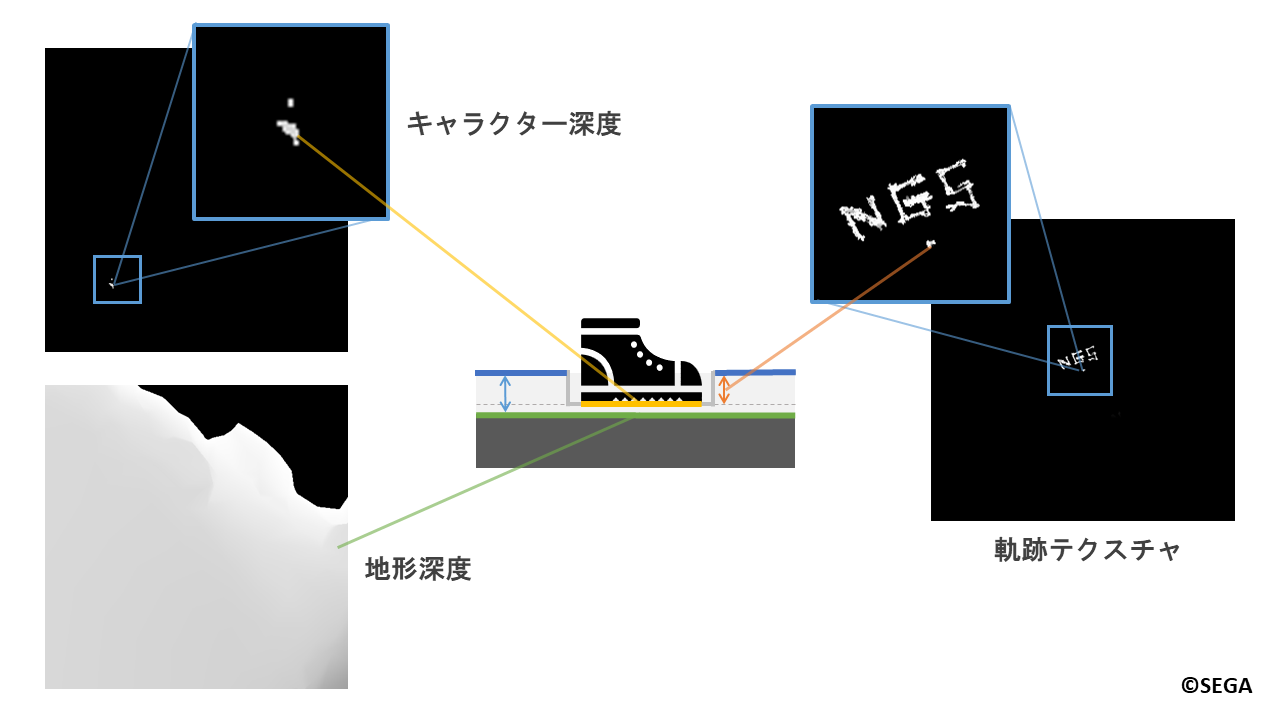
キャラクターの足によってどの位置でどの程度の深さまでへこませるかを決めるために、
カメラを地面の下から上方向に向けて地形とキャラクターに対して深度撮影を行います。
4.1.2.軌跡テクスチャの作成
次に、跡を付ける深さの情報が格納された軌跡テクスチャを作成します。
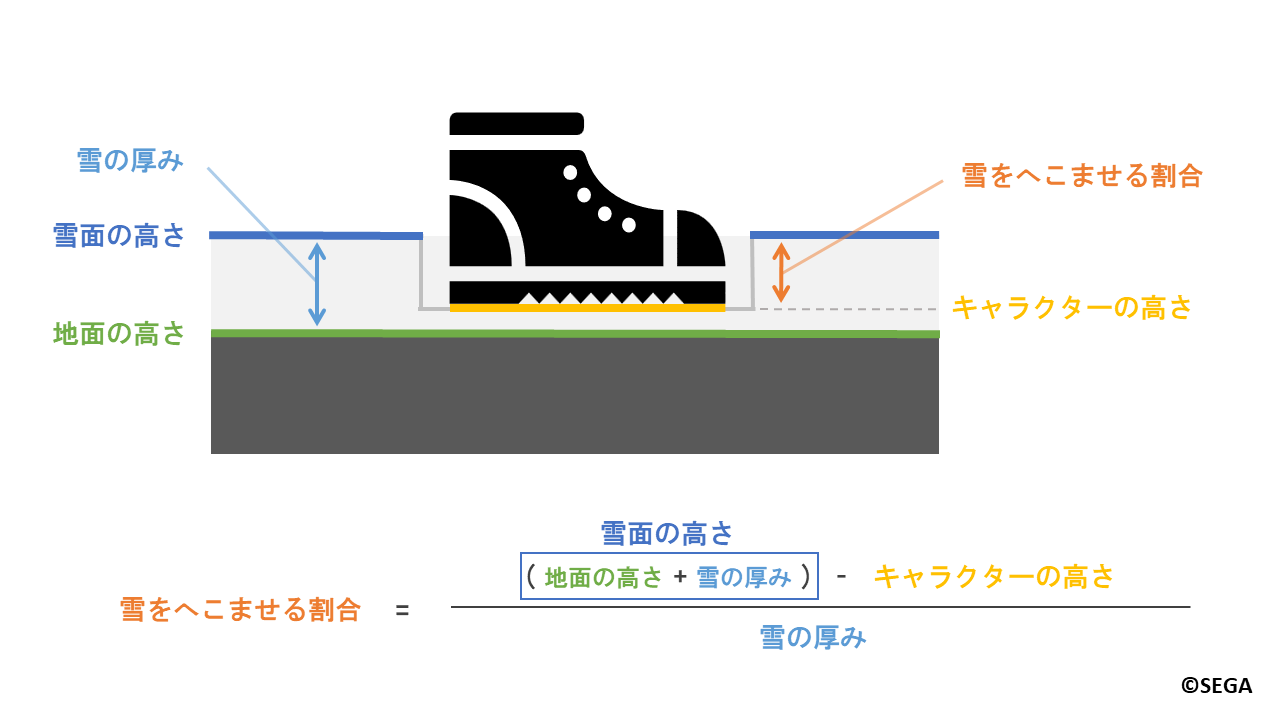
雪がへこむのは以下の図のように、キャラクターの足が地面と雪面の間にあるときです。
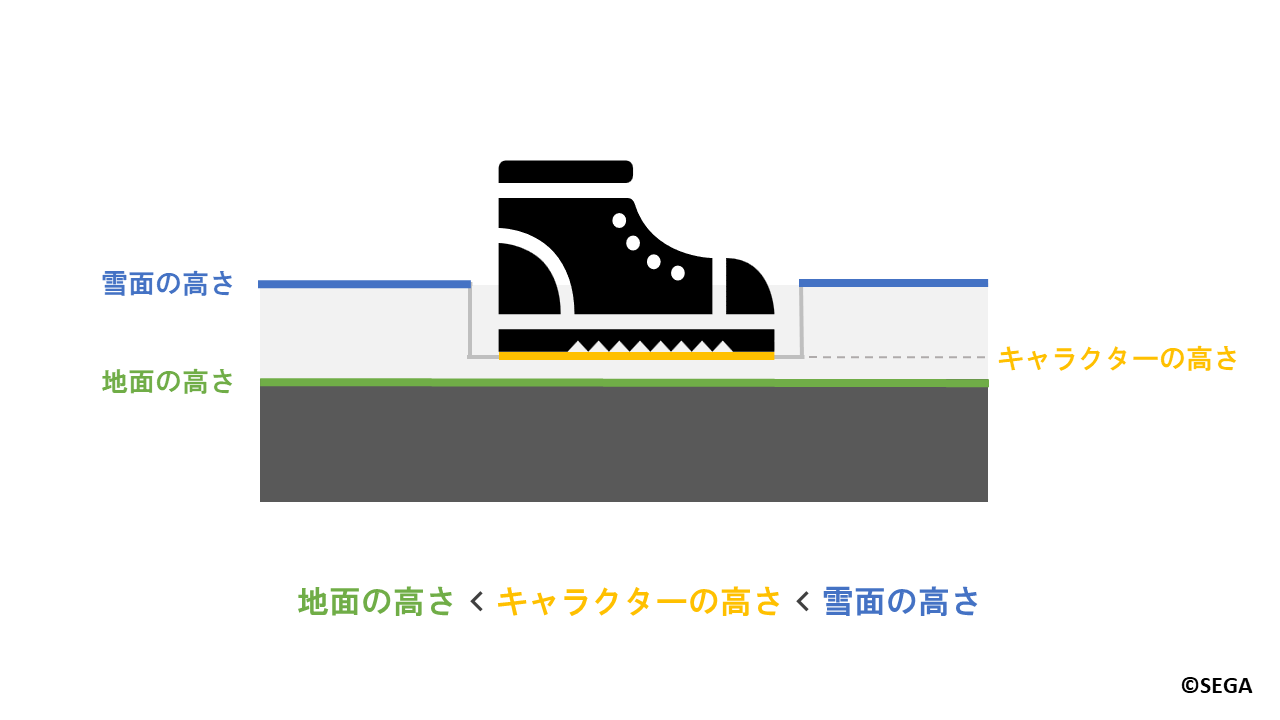
条件式で表すと以下のようになります。
地面の高さ < キャラクターの高さ < 雪面の高さ
ここでは説明のため、キャラクターの足の位置を「キャラクターの高さ」と表現します。
先ほどの深度撮影の結果を用いて
「キャラクターの高さ」はキャラクター深度から、「地面の高さ」は地形深度から求まります。
また、「雪面の高さ」は「地面の高さ」と「雪の厚み」を合わせた値です。
「雪の厚み」は内部的に設定されたパラメータで、場所によって厚みが異なります。
「雪をへこませる割合」は雪がへこんでいない状態を0.0、すべてへこんでいる状態を1.0として、
以下のように計算します。
雪をへこませる割合 = (地面の高さ + 雪の厚み - キャラクターの高さ) / 雪の厚み
シェーダーで計算された値は軌跡テクスチャへと書き込まれます。
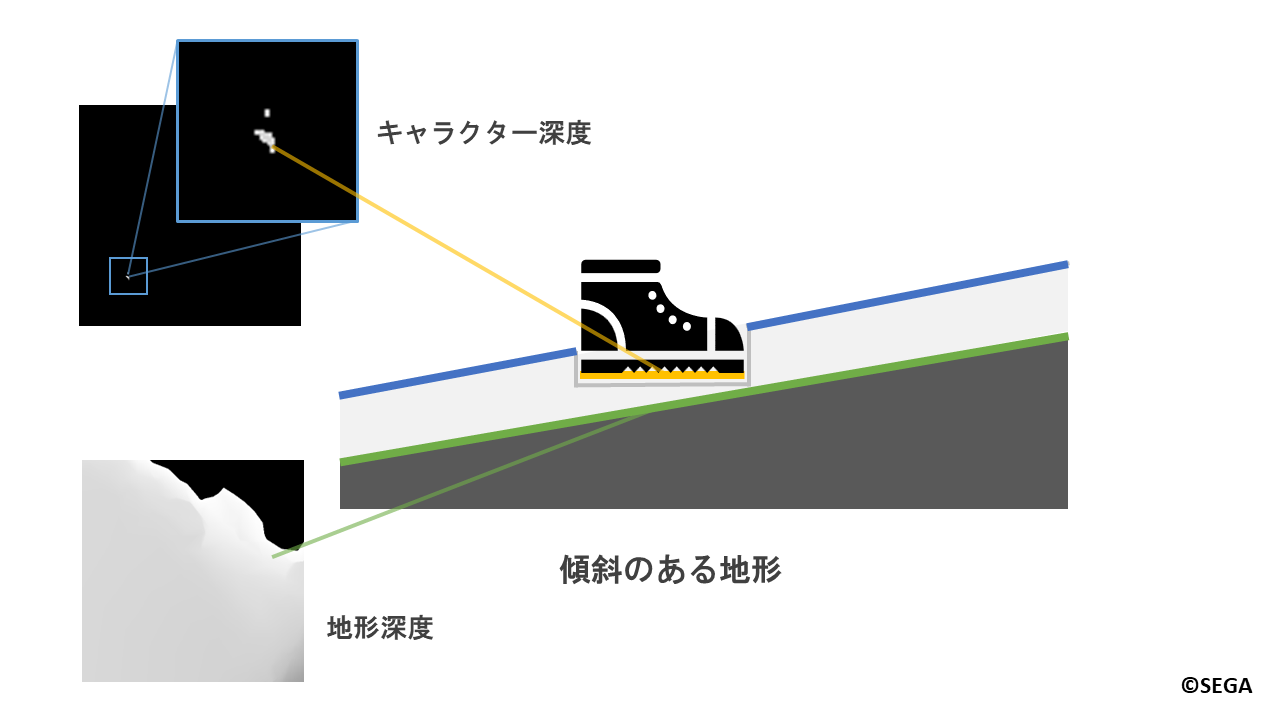
地形深度を用いているため、傾斜のある地形などでもへこませることができます。
4.1.2.1.軌跡テクスチャのフィルタ処理
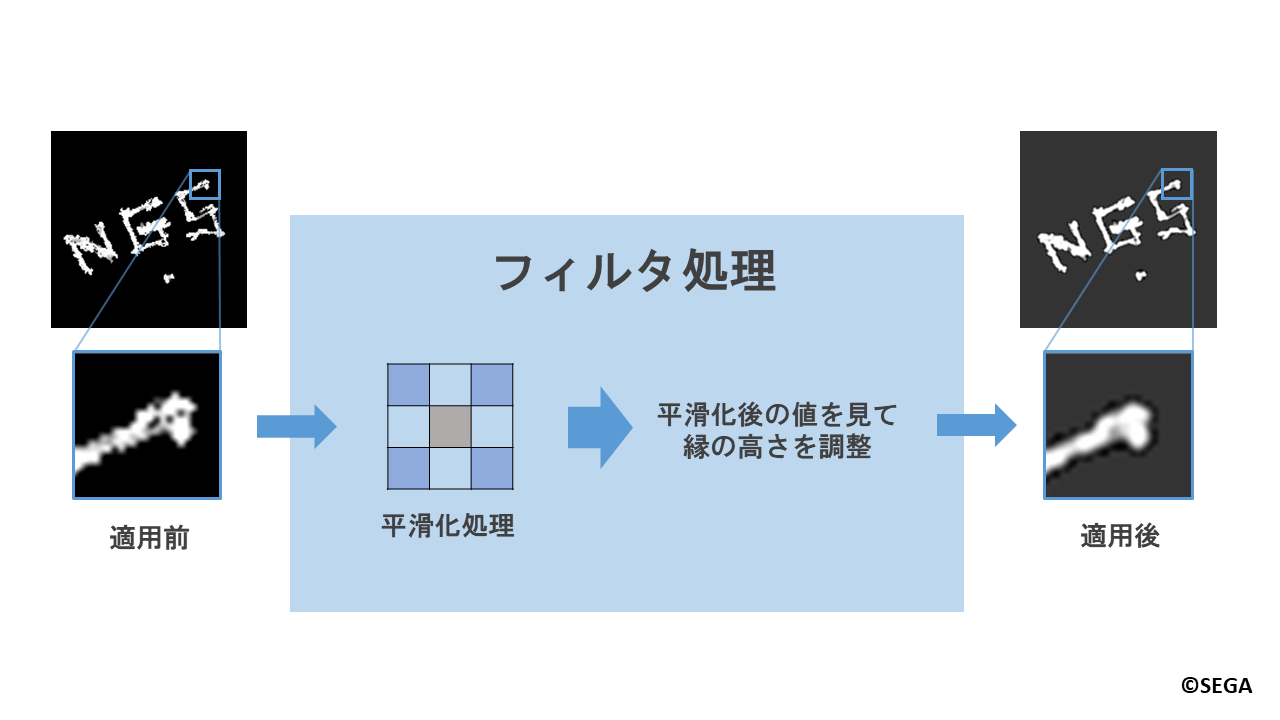
次に作成した軌跡テクスチャに対して、より自然なへこみ跡を表現するため、フィルタ処理をかけています。
ここで冒頭の写真を再度見てみましょう。

足跡と雪の縁の部分に着目してみると、足跡側ではへこみが緩やかに広がっています。
また、雪側では踏まれて押し出された雪によって盛り上がっていることがわかります。
これらを表現するために、フィルタ処理では平滑化を行い、へこみを緩やかにしたうえで、
へこみ部分の縁の高さを調整し隆起させています。
以下は実際のゲーム内でのフィルタ処理の有無の比較画像になります。
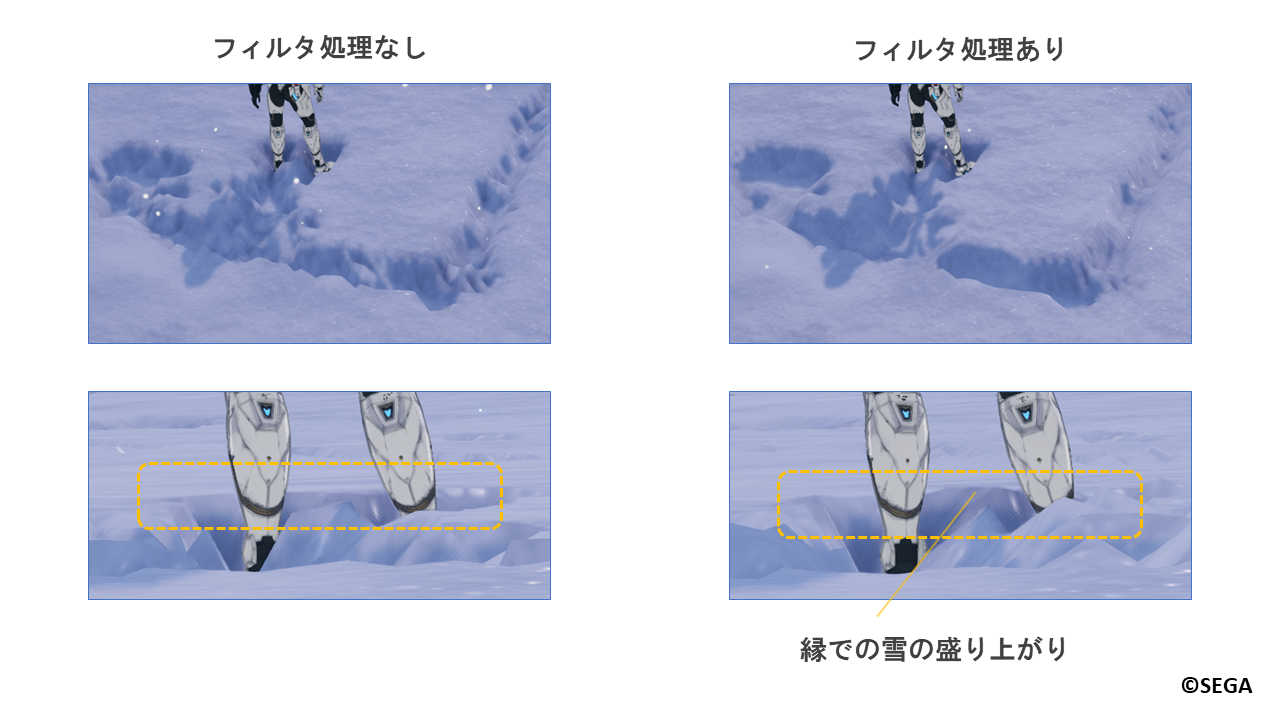
フィルタ処理をかけることで、全体的に滑らかな跡になり、縁部分での雪の盛り上がりも表現できています。
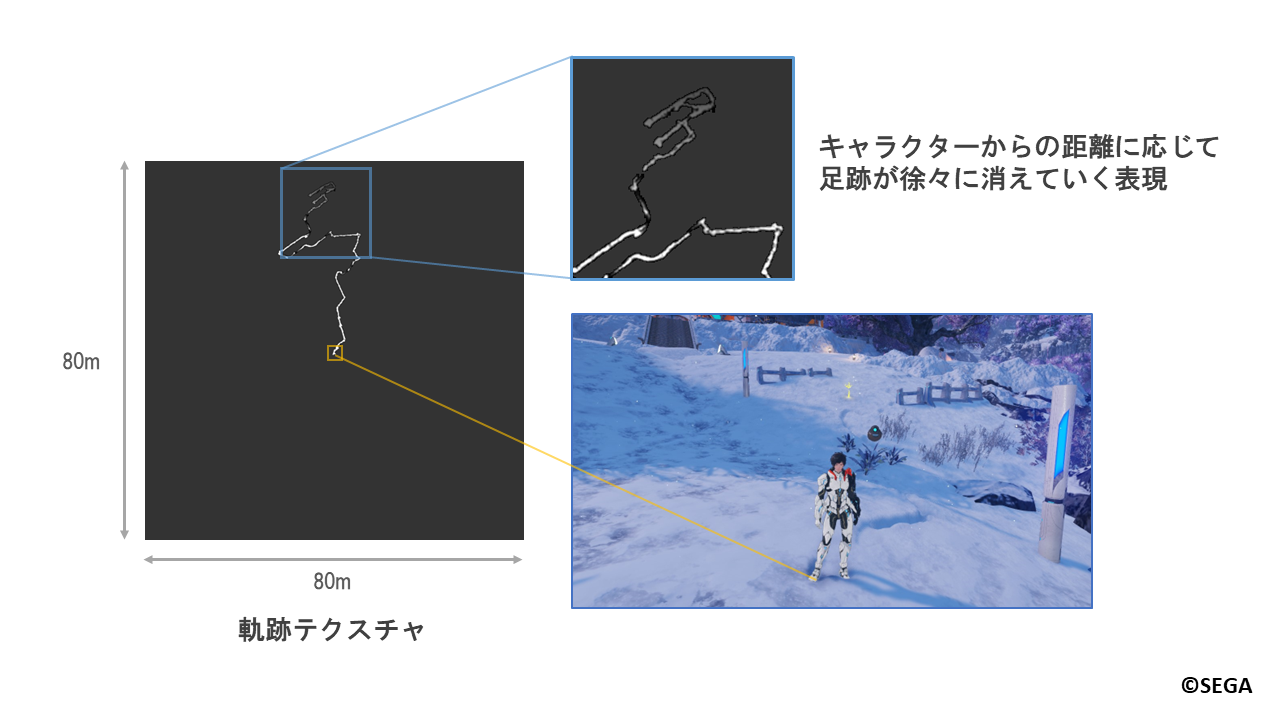
また、軌跡テクスチャにはプレイヤーキャラクターを中心として80m四方の範囲内の跡が記録されており、
プレイヤーキャラクターからの距離に応じて徐々に足跡が消えていく表現についてもフィルタ処理で行っています。
4.1.3.雪面の変形
最後は雪面の描画時に、作成した軌跡テクスチャの情報を元に雪面を変形させます。
雪面の変形にはテッセレーション処理を用います。
テッセレーション処理では地形モデルのポリゴンを分割し、分割されたポリゴンの頂点の位置を変更します。
頂点位置の変更の際に軌跡テクスチャを参照することで、跡付けを行う部分をへこませます。
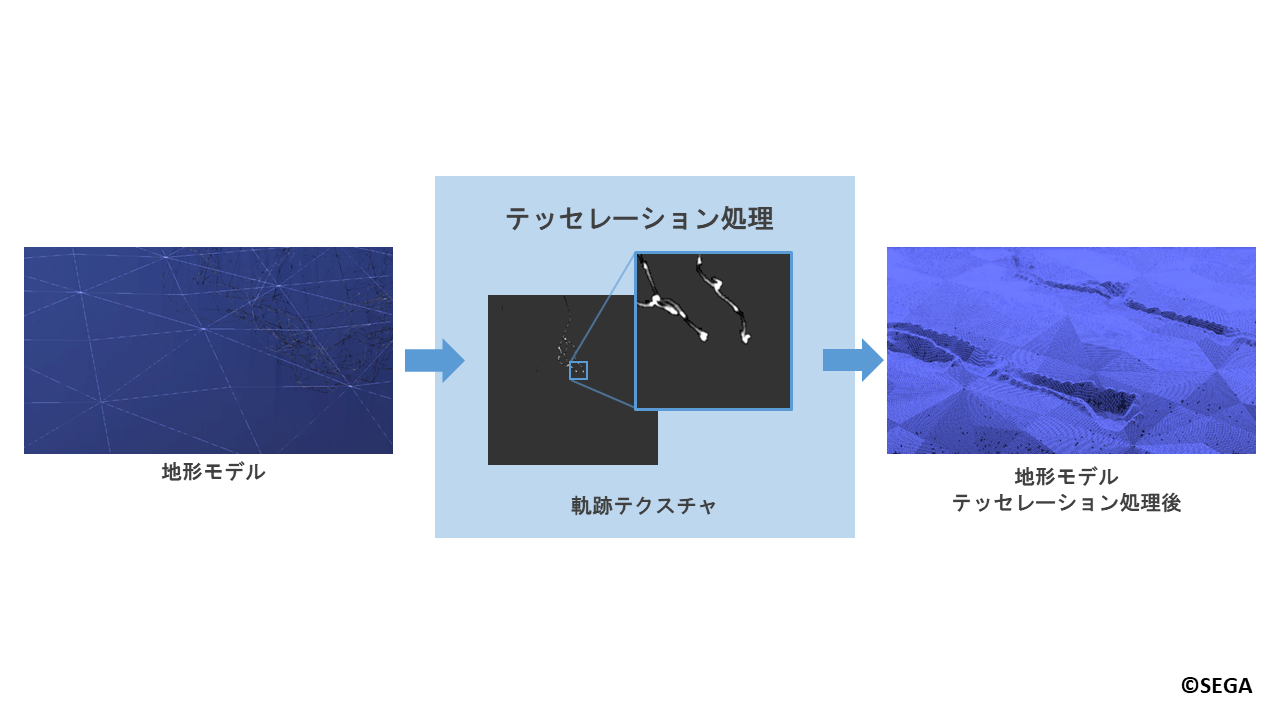
下記がテッセレーション処理の有無の比較画像になります。


ちなみに、テッセレーションに対応していない場合でも、軌跡テクスチャを用いた法線の調整やAOにより陰影をつけることで疑似的に表現しています。

5.ハウジングコンテンツでの雪原の跡付け表現
ここまではフィールドにおける雪原の跡付け表現について説明しました。
ここからは、『NGS』のハウジングコンテンツである、「クリエイティブスペース」の雪山風マップ
「クヴァリステーマ」における雪原の跡付け表現について説明します。

「クリエイティブスペース」内ではフィールドと同様のキャラクターによる雪への跡付けだけでなく、
プレイヤーが設置可能なオブジェクトである「ビルドパーツ」による跡付けにも対応しています。
5.1.オブジェクトよる跡付け表現
基本的な処理の流れについてはフィールドでの跡付けと同様です。
今回はオブジェクトによる跡付けを行うため、追加でオブジェクトに対する深度撮影を行い、
軌跡テクスチャ作成時にオブジェクトの高さも考慮します。
処理の流れは以下の通りです。
- オブジェクトに対する深度撮影
- 地形とキャラクターに対する深度撮影
- オブジェクトの深度を考慮した軌跡テクスチャの作成
- 雪面の変形
以降の説明では、1. と 3. について紹介します。
5.1.1.オブジェクトに対する深度撮影
まずは 「1. オブジェクトに対する深度撮影」についての説明です。
オブジェクトを設置する際にカメラを地面の下から上方向に向け、
オブジェクトの表面と背面の深度を撮影します。
描画結果は二枚のキャッシュテクスチャに格納されます。
表面と背面の両方で深度を描画する理由については後述します。
「クリエイティブスペース」ではオブジェクトの設置だけでなく、地形の高さも編集することができます。
オブジェクトに対する深度撮影の際には地形の編集が可能な、高さ100m、256m四方の範囲が収まるように
キャッシュテクスチャへ深度が書き込まれます。
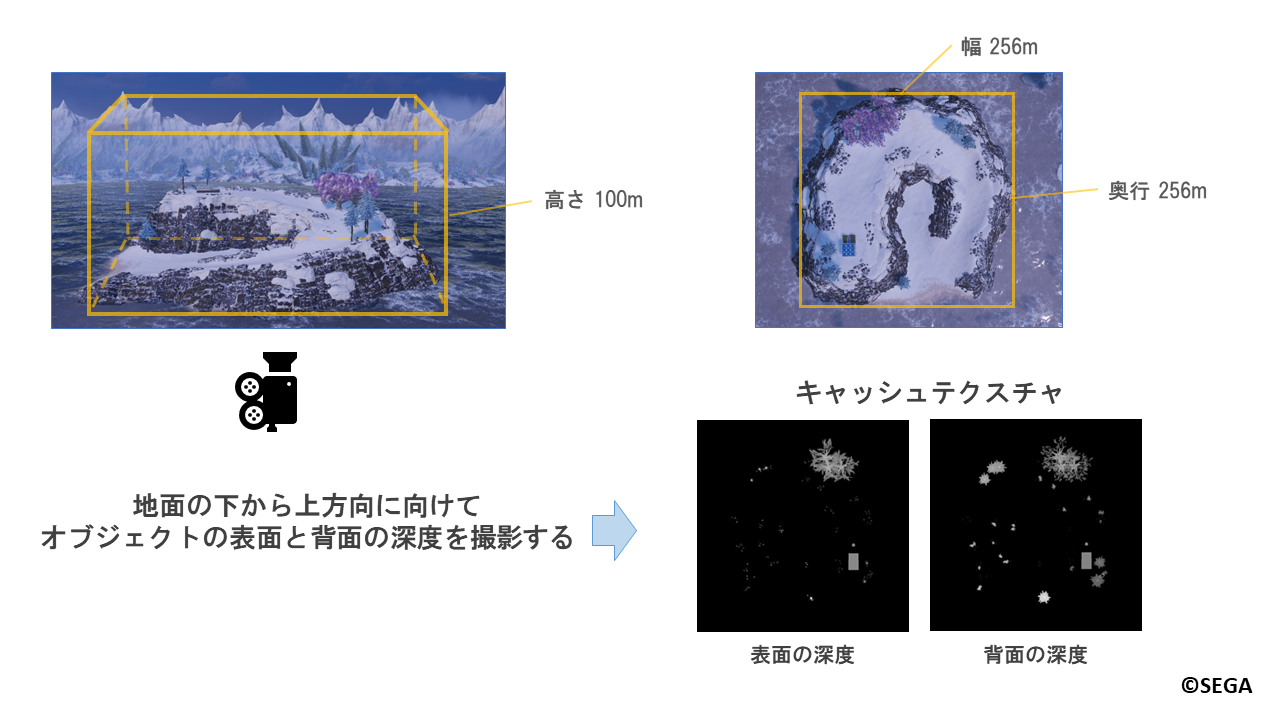
これによって「クリエイティブスペース」内にいる間は、オブジェクトの跡が付いた場所から離れても跡が残ります。
また、オブジェクトに対する深度撮影はオブジェクト設置時に一度だけ行うことで、
深度撮影による負荷を抑えています。

5.1.2.オブジェクトの深度を考慮した軌跡テクスチャの作成
次に「3. オブジェクトの深度を考慮した軌跡テクスチャの作成」について説明します。
オブジェクト深度の使い方について、
まずはキャラクターの場合と同じように深度テクスチャを一つだけ使う場合を考えてみましょう。
次のようなオブジェクトを設置します。

雪がへこむのは、オブジェクトの底面が地面と雪面の間にあるときです。
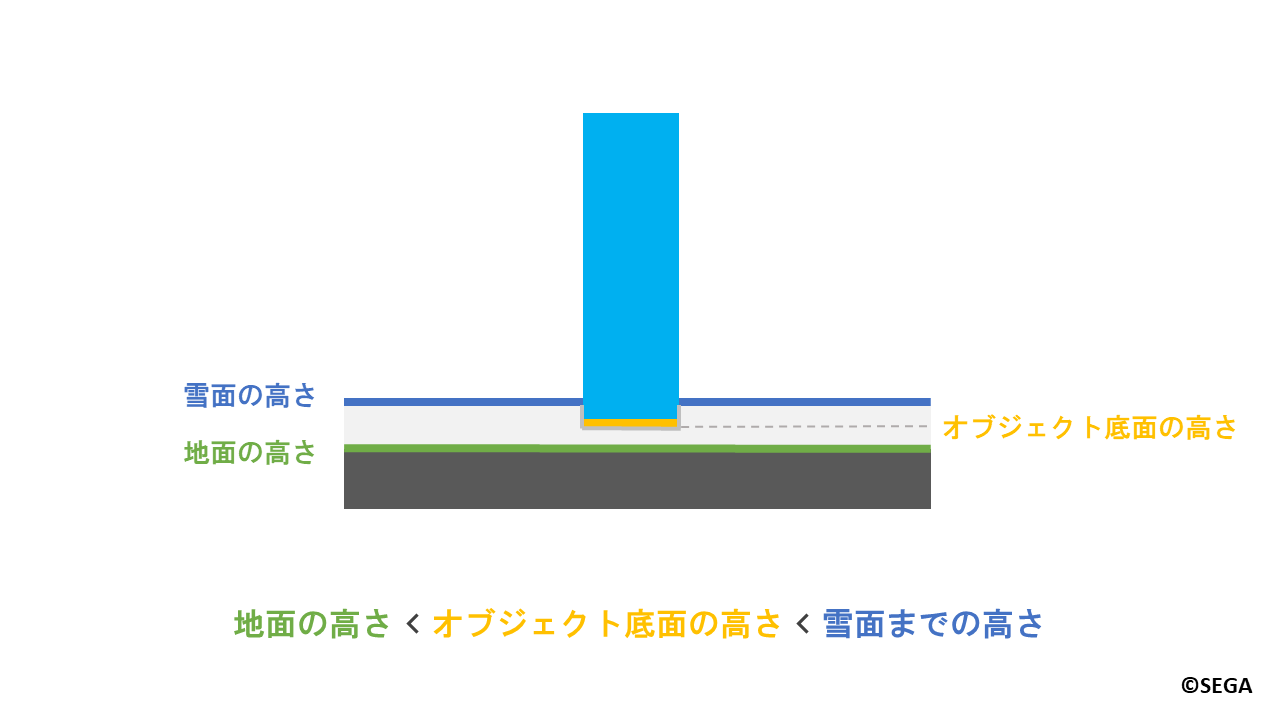
条件式で表すと以下のようになります。
地面の高さ < オブジェクト底面の高さ < 雪面の高さ
ここでオブジェクト底面の位置を、説明のため「オブジェクト底面の高さ」と表現します。
「オブジェクト底面の高さ」はカメラを地面の下から上方向に向け、
オブジェクトに対して深度撮影した、オブジェクトの表面の深度から求まります。
「雪をへこませる割合」についてもキャラクターの場合と同様に計算します。
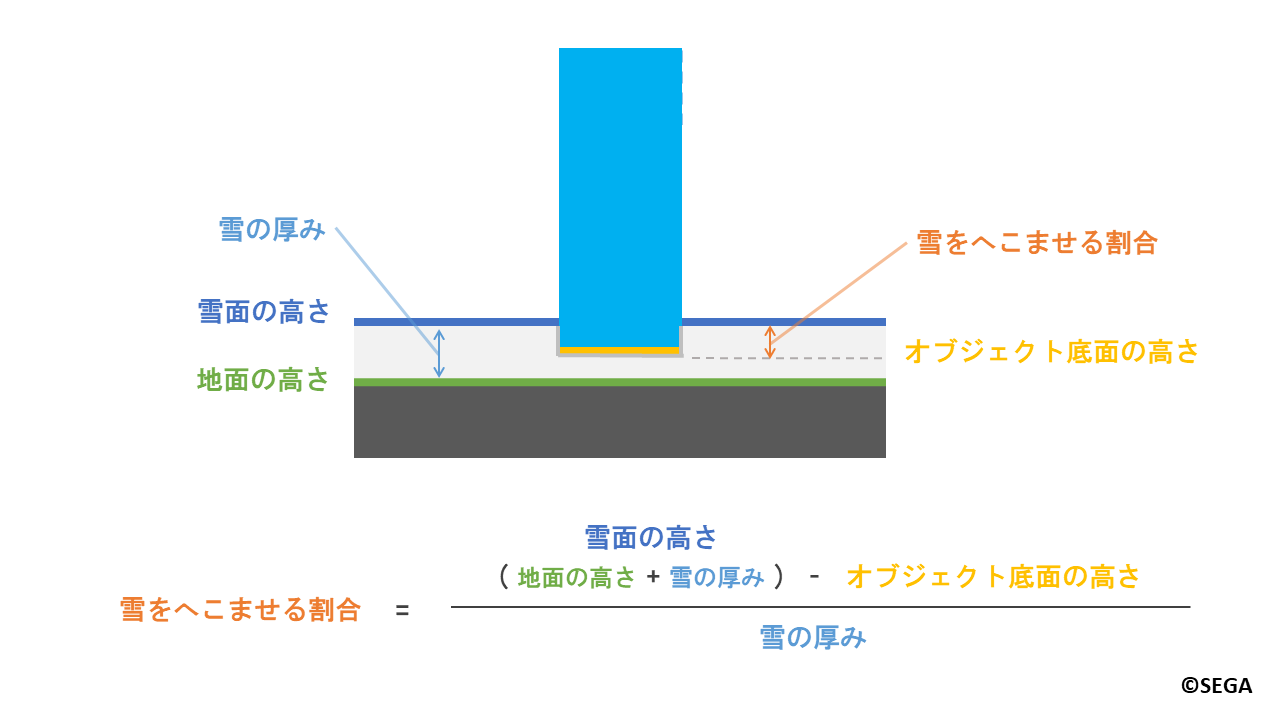
ここまではキャラクターの場合と同様に、オブジェクト表面のみの深度撮影で問題なさそうです。
では次のケースを見ていきましょう。
「クリエイティブスペース」ではプレイヤーが自由にオブジェクトを設置でき、
地形の高さも編集できるため、オブジェクトが地形に埋まる場合があります。
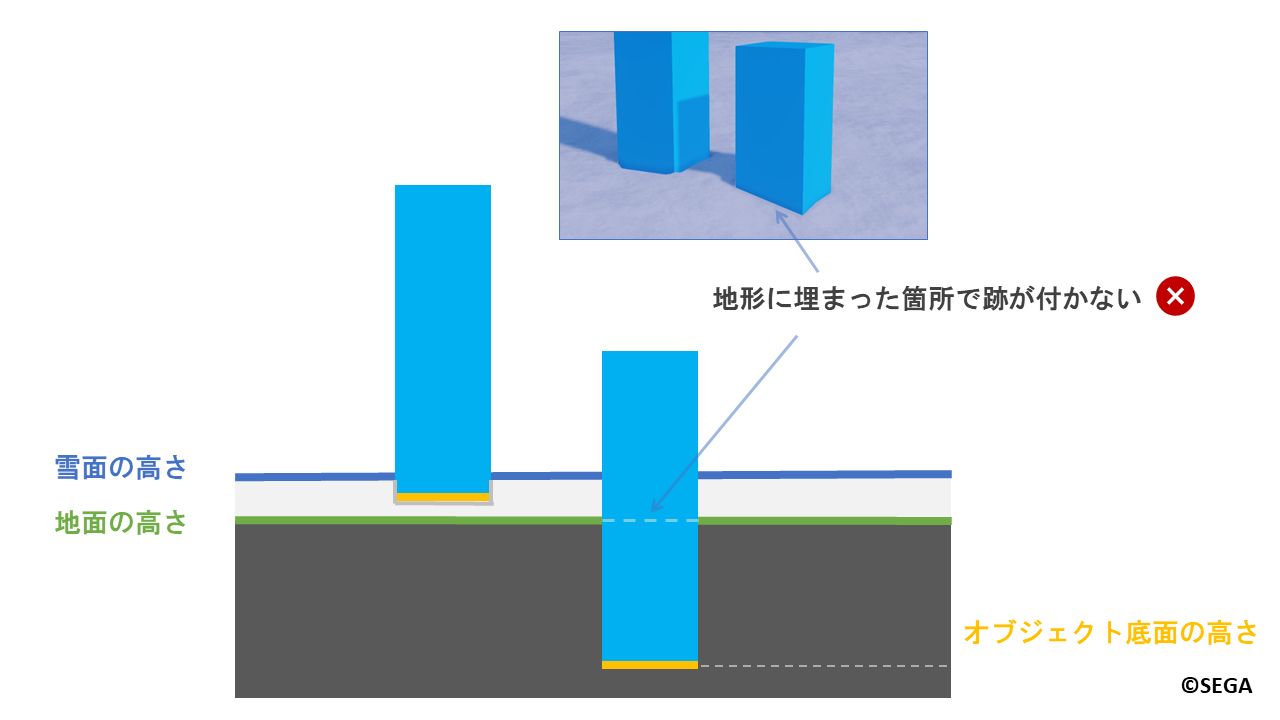
以下のようにオブジェクトを地形に埋めた状態で配置する場合はどうでしょうか?

地形に埋まった状態で設置した場合、オブジェクトの底面が地面よりも低くなってしまい、
埋まった箇所で跡が付きません。
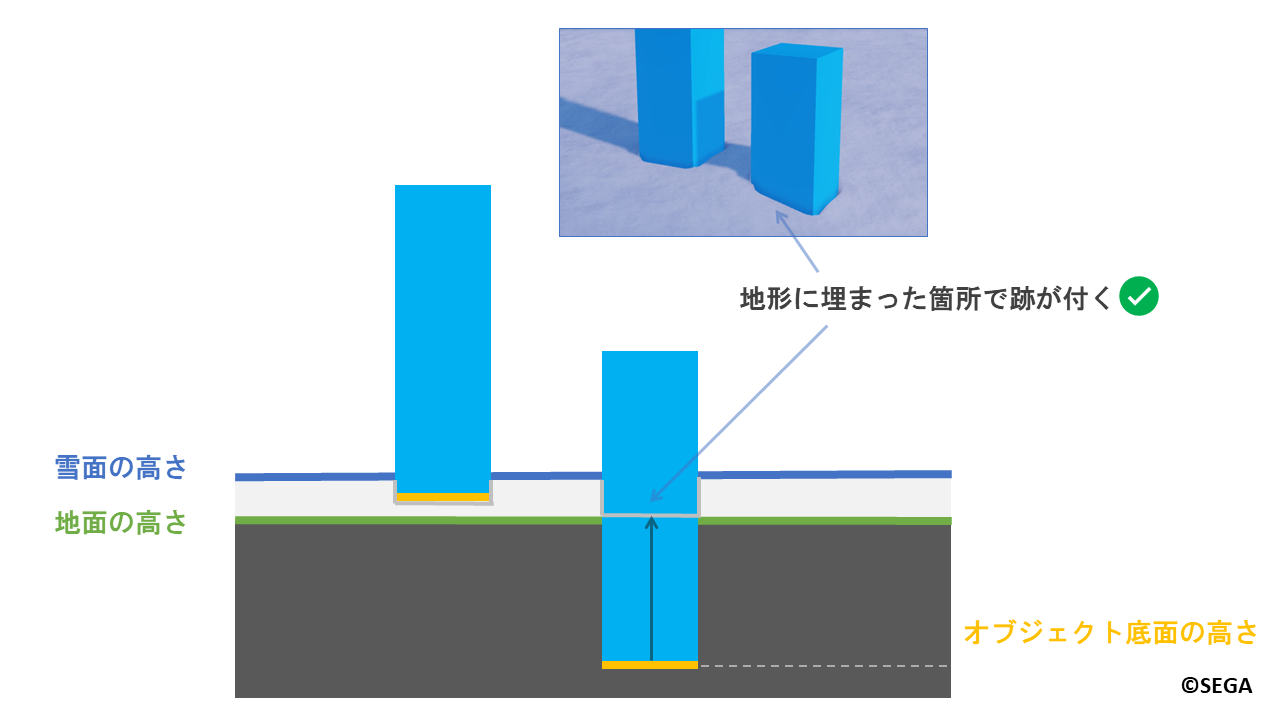
そこで、地面の高さよりも低い位置にオブジェクト底面が来た場合は、
「雪をへこませる割合」を1.0とし、雪をすべてへこませます。
この場合は以下のように地形に埋まった箇所でも跡を付けることができます。
しかし、上記の改善を加えた場合でも別の問題が二つ起きてしまいます。
次で詳しく見ていきましょう。
5.1.2.1.オブジェクトの深度撮影が表面のみの場合に起きる問題
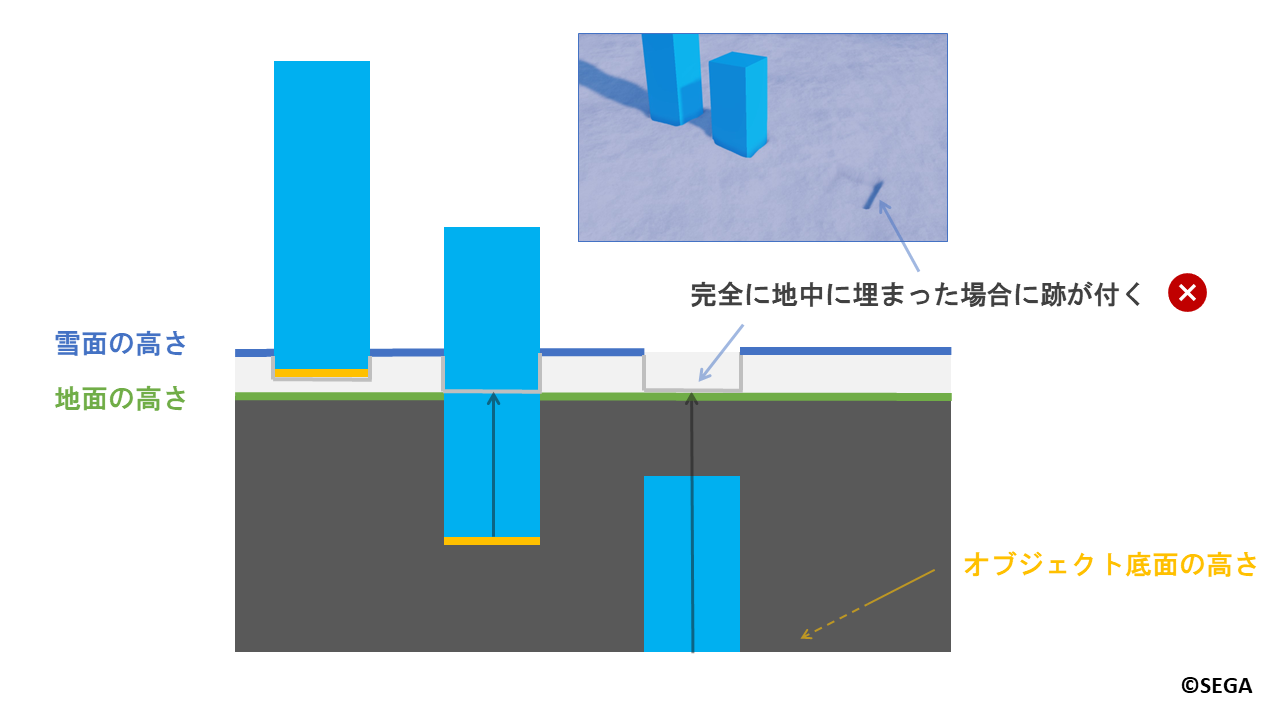
まず一つ目はオブジェクトが完全に地中に埋まってしまった場合です。

この場合だと「オブジェクト底面の高さ」だけではオブジェクトが完全に埋まったかの判定が取れず、
以下のように不自然に跡が付いてしまいます。
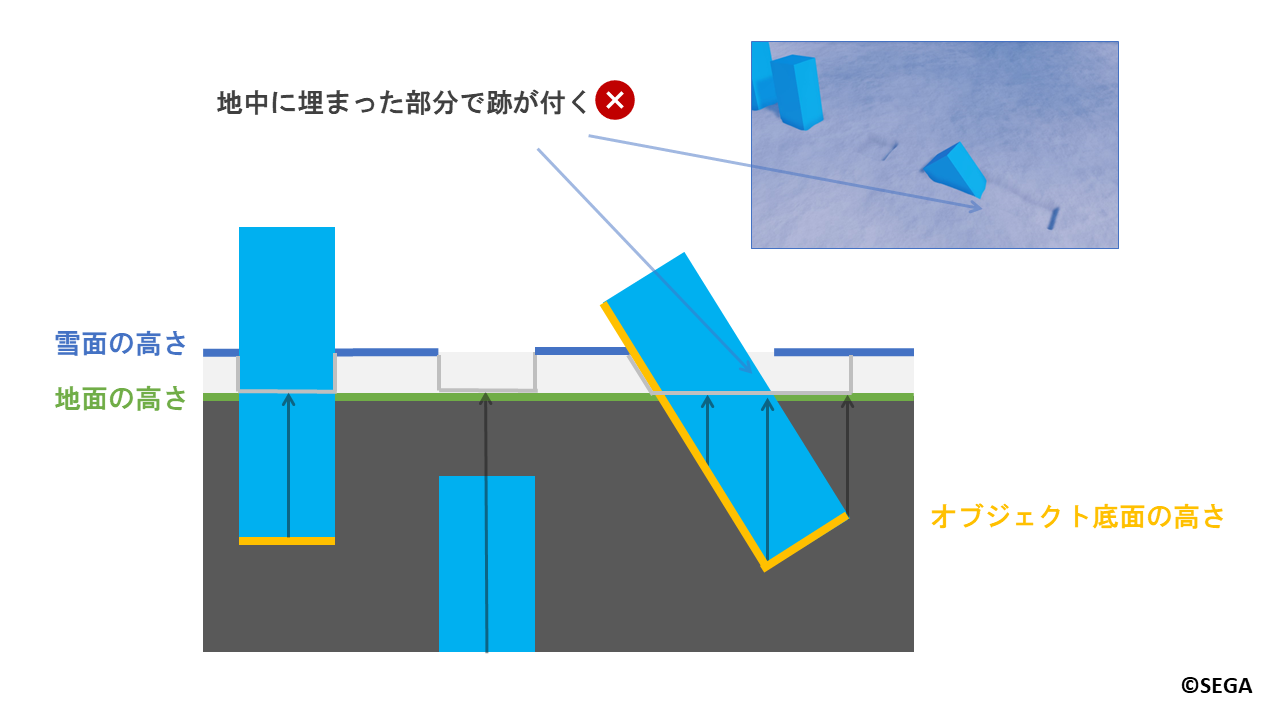
二つ目の問題はオブジェクトを回転させたときに起きます。
先ほどのオブジェクトを次のように回転させ、一部地中に埋まった状態で設置する場合を考えてみましょう。

この場合も完全に埋まった場合と同様に、地中に埋まって隠れってしまった部分で不自然に跡が付いてしまいます。
これらの問題に対応するために、オブジェクトに関しては表面と裏面の両面で深度を描画しています。
表面と裏面の深度の使い方について、先ほど回転させて設置した場合を例に見ていきます。
まず、オブジェクトの上面が地面よりも上にくる領域に着目します。
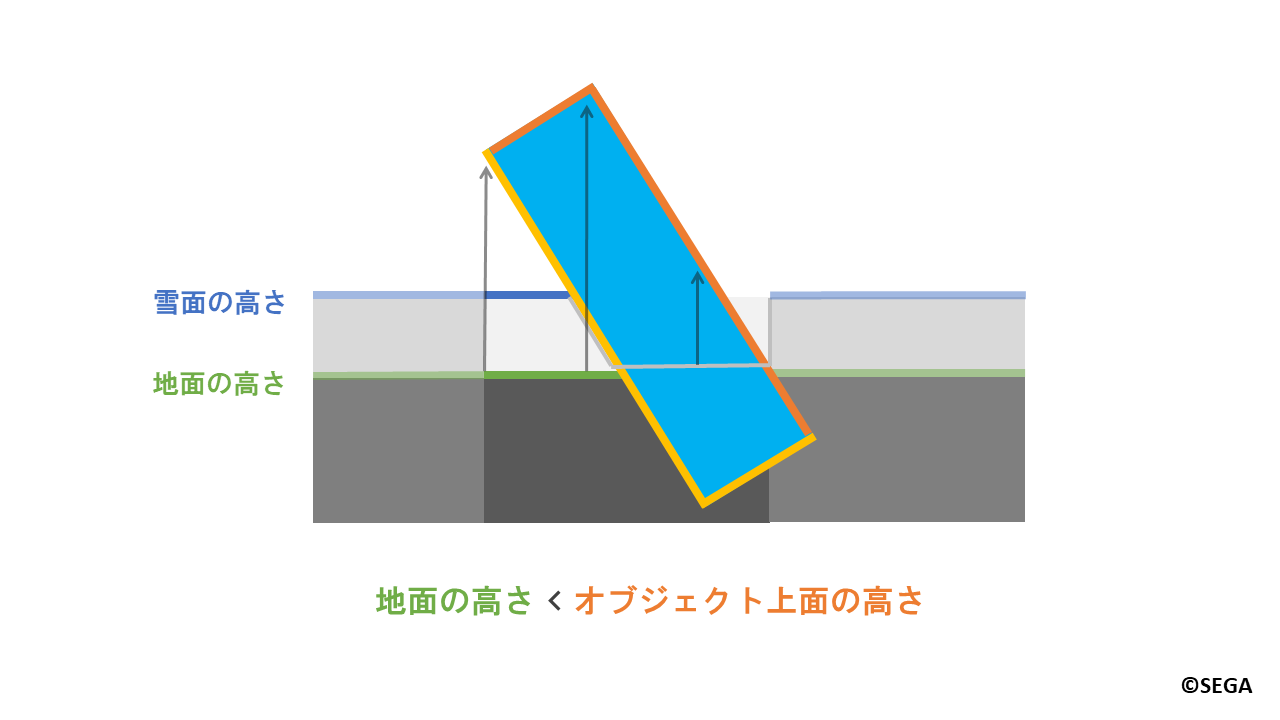
条件としては以下のようになります。
地面の高さ < オブジェクト上面の高さ
ここでも底面と同様に、オブジェクト上面の位置を、説明のため「オブジェクト上面の高さ」と表現します。
「オブジェクト上面の高さ」はカメラを地面の下から上方向に向け、オブジェクトに対して深度撮影した、
オブジェクトの背面の深度から求まります。
次に、「オブジェクト底面の高さ」を用いて雪をへこませる部分を決めます。
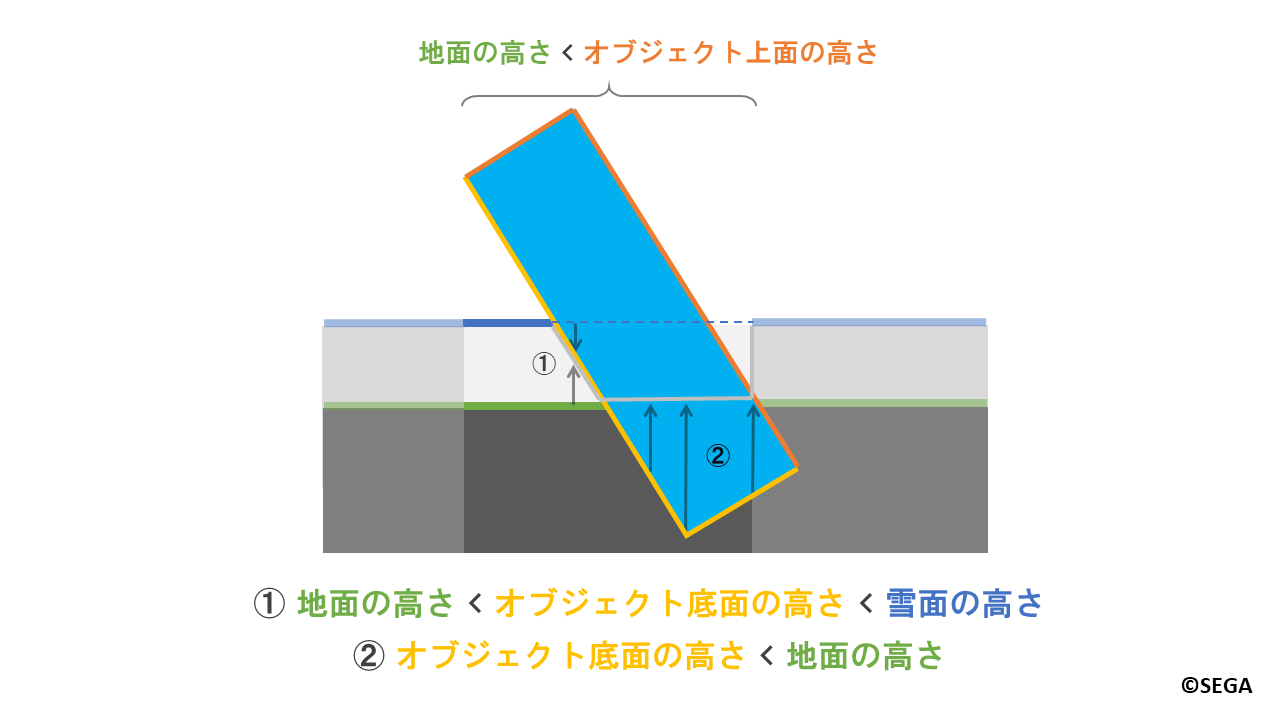
上図の①のように、オブジェクト底面が地面と雪面の間にくる場合は、先ほどの説明の通り、
キャラクターでの跡付けと同様の方法で「雪をへこませる割合」を計算します。
また、上図の②のようにオブジェクトの底面が地面よりも下にくる場合は、
「雪をへこませる割合」を1.0とし、雪をすべてへこませます。
これにより、オブジェクトが完全に地中に埋まってしまう場合や、
一部だけ埋まってしまう場合に対しても自然な跡付けを行うことができます。

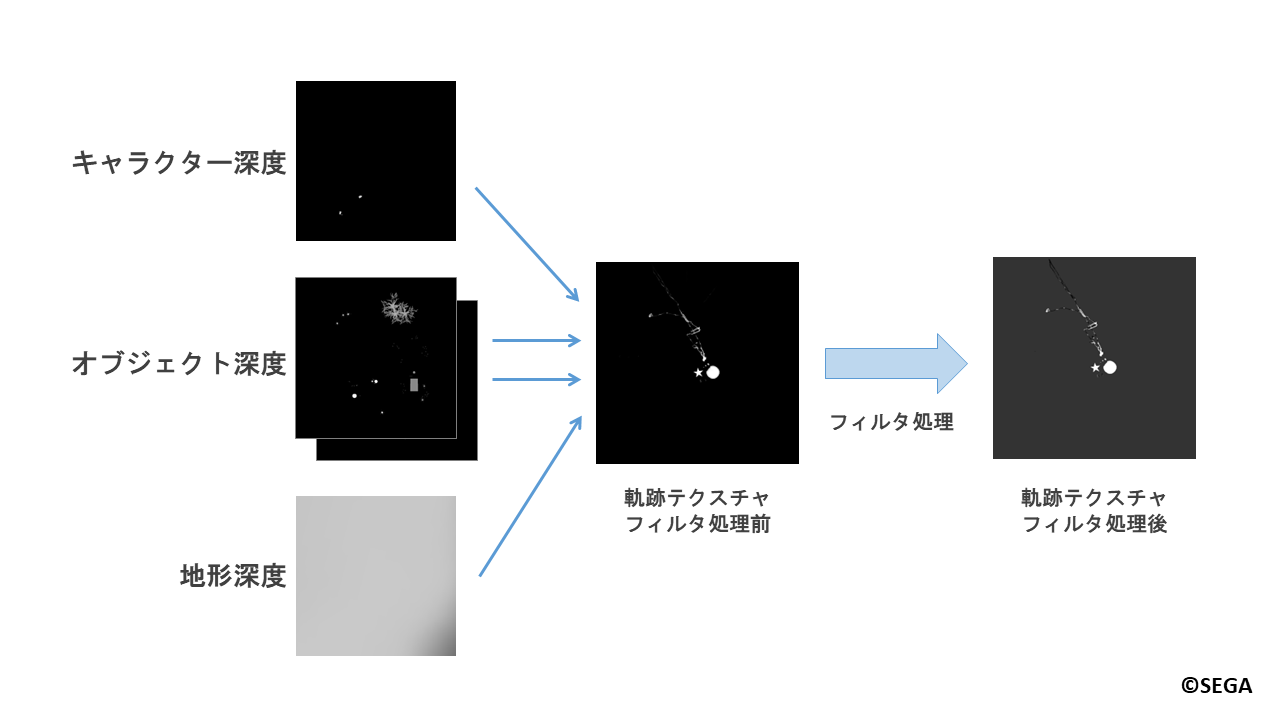
最終的に二枚のキャッシュテクスチャに保存されたオブジェクト深度、キャラクター深度、
地形深度を用いて軌跡を描き、キャラクターの跡付けの際と同様のフィルタ処理を経て、
「クリエイティブスペース」での軌跡テクスチャができます。
6.まとめ
今回『NGS』における雪原表現について、フィールドとハウジングコンテンツにおける事例を紹介しました。
フィールドではキャラクターの足跡による跡付け、
ハウジングコンテンツでは自由な配置を踏まえたオブジェクトによる跡付けについて説明させていただきました。
現実世界は目を引く景色、心を動かす風景、興味深い光学現象であふれています。
それらを注意深く観察し、ゲームに落とし込むことでさらに感動を与える表現が生まれると思っています。
今回紹介した手法は目新しいものではありませんが、何かの参考になりましたら幸いです。
7.最後に
セガでは一緒に働く仲間を募集しています。
共に感動体験を色々な人に提供できるようなゲームとそのグラフィックス表現を作りませんか?
もしご興味を持たれましたら下記のサイトにアクセスをお願いいたします。